Frame matching
Frame matching is the task of matching two or more bundles features with each other. It's used to do
- classification (A matches B therefore A is a kind of B), also known as concept recognition
- similarity judgment (A partially matches B, so A is similar to B)
- case-based reasoning (A is the best partial match to B that can be found in memory, so use the information attached to A when processing B)
We'll talk about classification / concept recognition first. The input is a concept with some additional features, e.g., an animal that's furry and jumps high. In a knowledge base that included kangaroos, kangaroos should be recognized as a possibility.
The basic algorithm is to start with the input concept, then work down the hiearchy to each specialization compatible with the input features. The result is a list of one or more concepts. There has to be at least one, namely the original input concept.
The basic rule for compatibility, i.e., frame matching, is simple. Given two sets of features, which we'll represent as frames with roles and fillers, abst and spec, (for "potential abstraction" and "potential specialization"), then:
spec matches abst if every slot in abst has a corresponding matching slot in spec.
Slot matching has a similarly simple rule:
A slot in spec matches the corresponding slot in abst if the filler of that slot in spec is equal to or a specialization of the filler in abst.
Intuitively, abst is a set of properties that spec needs to have to be counted as being a kind of abst.
There are several important properties of these rules:
- Slots in spec not mentioned by abst are ignored. They're extra information that doesn't affect the match.
- A frame matches itself.
- A frame with no slots matches everything.
Because of this last property, we normally need to treat slotless abstractions specially. For example, suppose we had a hierarchy of animals like this:
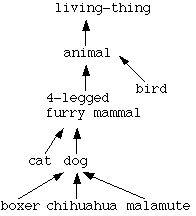
with no slots on cat or dog. Now suppose we are trying to store a new four-legged mammal concept. With no slots, the new concept could just as easily go under cat as under dog, or even both! There's simply no information to say whether the new concept is a cat or a dog.
It would be nice to say "don't define slotless abstractions." Unfortunately, they're simply too useful, both as placeholders for concepts that we know exist, but for which we can't easily specify how to recognize them, and for concepts that are combinations of other concepts (see below).
Therefore, when writing a concept classifier using frame matching, we have to be careful to write code that handles slotless abstractions in some way appropriate to our needs.
Learning New Frames
Learning new frames can arise for several reasons.
- A new combination of concepts could be encountered. This leads to the construction of a new specialization of existing concepts.
- Or, commonalities between several existing concepts could be noted, leading to the construction of a new abstraction of existing concepts.
Learning From Specialization
Concept recognition returns concepts compatible with a set of input features, that is, concepts with no slots inconsistent with the input. There are two possibilities at this point:
- Every role and filler in the input is found in at least one of the recognized concepts, or
- The input includes more information, either additional slots or more specific fillers, or a different combination of slots, than any of the retrieved concepts.
In the first case, the input has no new information. For example, if the input was an animal with fur that jumps high, and concept recognition returns kangaroos, then we can assume for now that's what the input was referring to. If recognition returns kangaroos and kangaroo rats, we don't know what to choose but we still know we've seen things like that before.
In the second case, the knowledge base has failed to recognize the input. The input is referring to a concept new to the knowledge base. Hence, one form of learning would be to add the input to the knowledge base. How should this be done?
Recognition returned a list of concepts compatible with the input. However, no child of any those concepts was compatible. Therefore, the input should be installed under the concepts that were recognized. That is, the new concept should have the concepts returned by recognition as its immediate abstractions.
Only those slots not inheritable from any of the abstractions, i.e., the new information, need to be included with the new concept. This might mean that the new concept has no slots of its own! For example, suppose we had a knowledge base with the concept SMALL-THING and another concept RED-THING, each with the obvious slots. Suppose the input is the system's first encounter with a small red thing. The new concept would have SMALL-THING and RED-THING as its immediate abstractions, but it would neither have nor need any slots of its own. It's a slotless abstraction, that captures a conjunction of features not seen before.
In pseudo-code, the algorithm for learning in this case is:
LET absts = FIND-MATCHES(concept, slots)
IF NOTANY abst IN absts
SUCH THAT INCLUDES-ALL-SLOTS(abst, slots)
LET new-slots = FIND-NEW-SLOTS(slots, absts)
ADD-CONCEPT(concept, absts, new-slots)
Again, new-slots might be empty but the new concept should still be added.
Learning From Generalization
Another trigger for adding new concepts to a knowledge base is noticing that two or more existing concepts share one or more common features. Therefore, we might want the system to learn a new concept that captures the shared abstraction.
To do this, we need a partial matching algorithm that takes two frames and determines what's in common between them. For example, given the MOPs in mop-examples.lisp,
(find-commonalities 'i-gillfish-climb-trees 'i-walrus-lift-with-tusks)
might produce the following, listing the ancestors in common, and, for each slot, the ancestors of the fillers in common.
((M-ANIMAL-MOTION-EXAMPLE) (:ANIMAL M-ANIMAL)
(:FEATURE M-HEAD-PART) (:ACTION M-LIFT-SELF) (:BEHAVIOR M-BEHAVIOR))
Here's a sketch of the code:
(defun find-commonalities (mop1 mop2)
(cons
(find-common-absts mop1 mop2)
(find-common-slots mop1 mop2)))
find-commonalities simply passes the buck to the functions for finding
common ancestors and common slots.
(defun find-common-absts (mop1 mop2)
(remove-redundant-absts
(intersection (all-absts-of mop1)
(all-absts-of mop2))))
remove-redundant-absts is an internal MOPS function that takes a
list of concepts and returns a list of just those concepts that
have no specializations in the original list, other than
themselves. E.g.,
> (remove-redundant-absts '(m-chihuahua m-animal m-pet m-mammal)) (M-CHIHUAHUA M-PET)
The above definition of find-common-ancestors captures the idea but is a very inefficient way to do it. intersection generates a list and remove-redundant-absts throws away most of what's in there.
A better way would be to take the two lists of abstractions and find the most specific common elements directly, without the intermediate lists. This is left as an exercise for the reader.
Things become a little more complex with find-common-slots. The basic idea is simple: for all the slots in common, find the common ancestors of their fillers. This can be implemented as a loop that goes through a list of slots, gets the filler of that slot in each mop, and then compares the fillers using find-common-absts.
But where should the list of slots come from? The simple solution to append the slots from both MOPs, then compare.
(defun find-common-slots (mop1 mop2)
(loop for role in (union (roles-of mop1) (roles-of mop2))
for filler1 = (role-filler mop1 role)
for filler2 = (role-filler mop2 role)
for absts = (find-common-absts filler1 filler2)
unless (null absts)
collect (cons role absts)))
Notice that we can't just go down the slots of one MOP or the other, because of inheritance. For example, suppose we have Buddy, the chihuahua, and a nameless mole rat. Both are small, relatively hairless, four legged, and so on. However, the nameless mole rat may have no slots on it, other than perhaps an age. Buddy has an age and, being a pet, a name. If we used just the explicit slots on one or both the mops, we'd find nothing in common between Buddy and the mole rat, except that they both have an age.
Code to do this simple form of generalization can be found here.